もともとの論文には,Transformer は encoder と decoder を含む構造として記載されています.
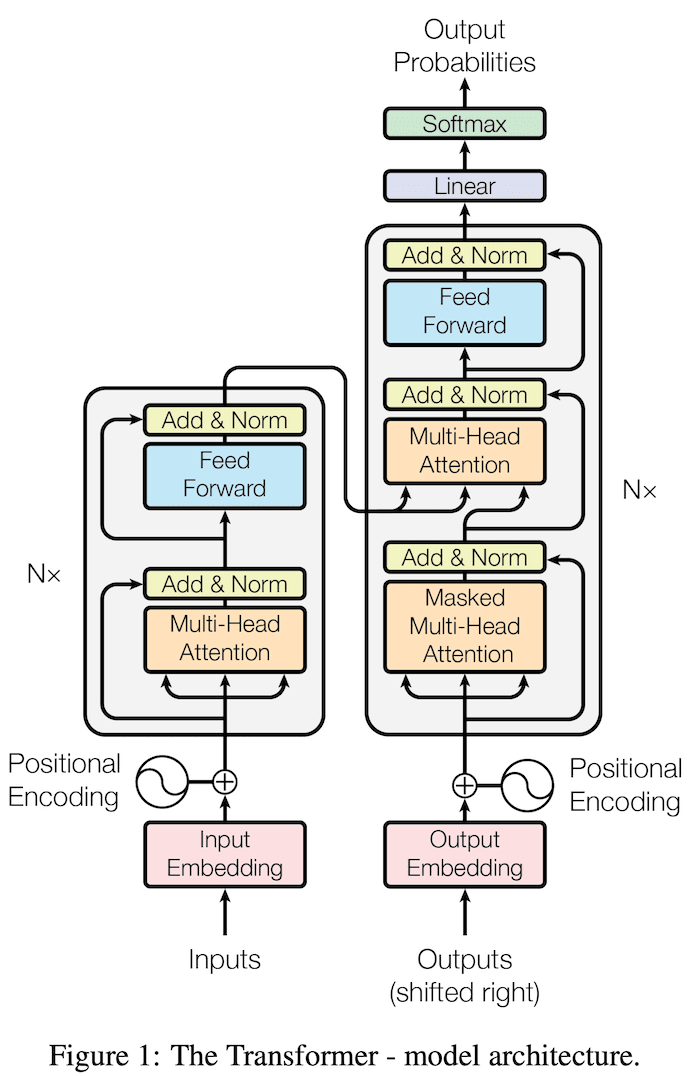
もう少しわかりやすい図があったので紹介します.
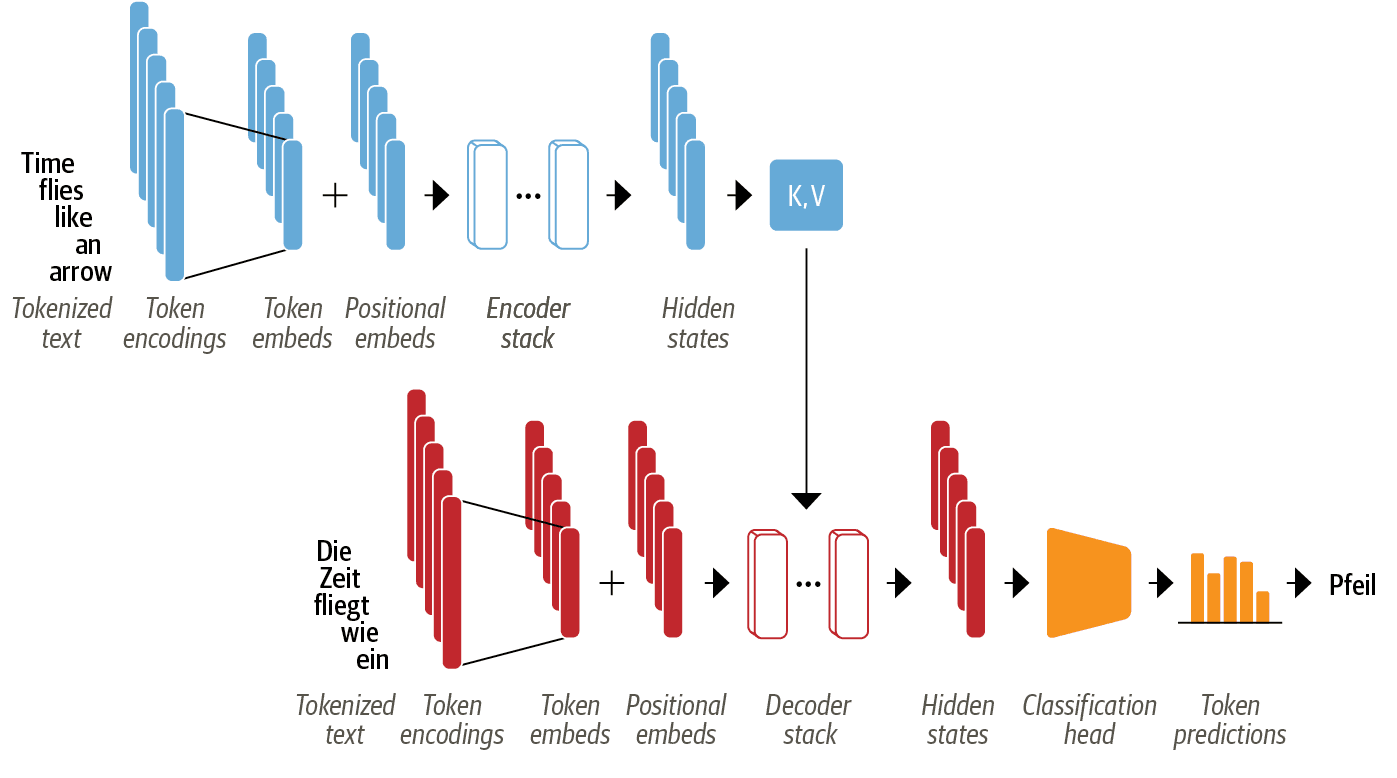
Encoder / Decoder
実際には encoder と decoder はどちらかがあればモデルとして成立するので, encoder-only, decoder-only, encoder-decoder の3種類に大きく分類されます.それぞれで改良が加えられて,たくさんのモデルが乱立しています.

- encoder-only: 入力シークエンスを解析するので,テキスト分類や固有表現抽出に用いられることが多いです.
- decoder-only: 次々に予測していくので,テキスト生成に用いられることが多いです.
- encoder-decoder: シークエンスを対応させていくので,機械翻訳や要約に用いられることが多いです.
なお,使い方によっては異なるタスクに対応させることも可能なので,完全に分類させるものではありません.
効率化
もともとの構造では O(n2) となるので規模を大きくしにくいという欠点がありました.
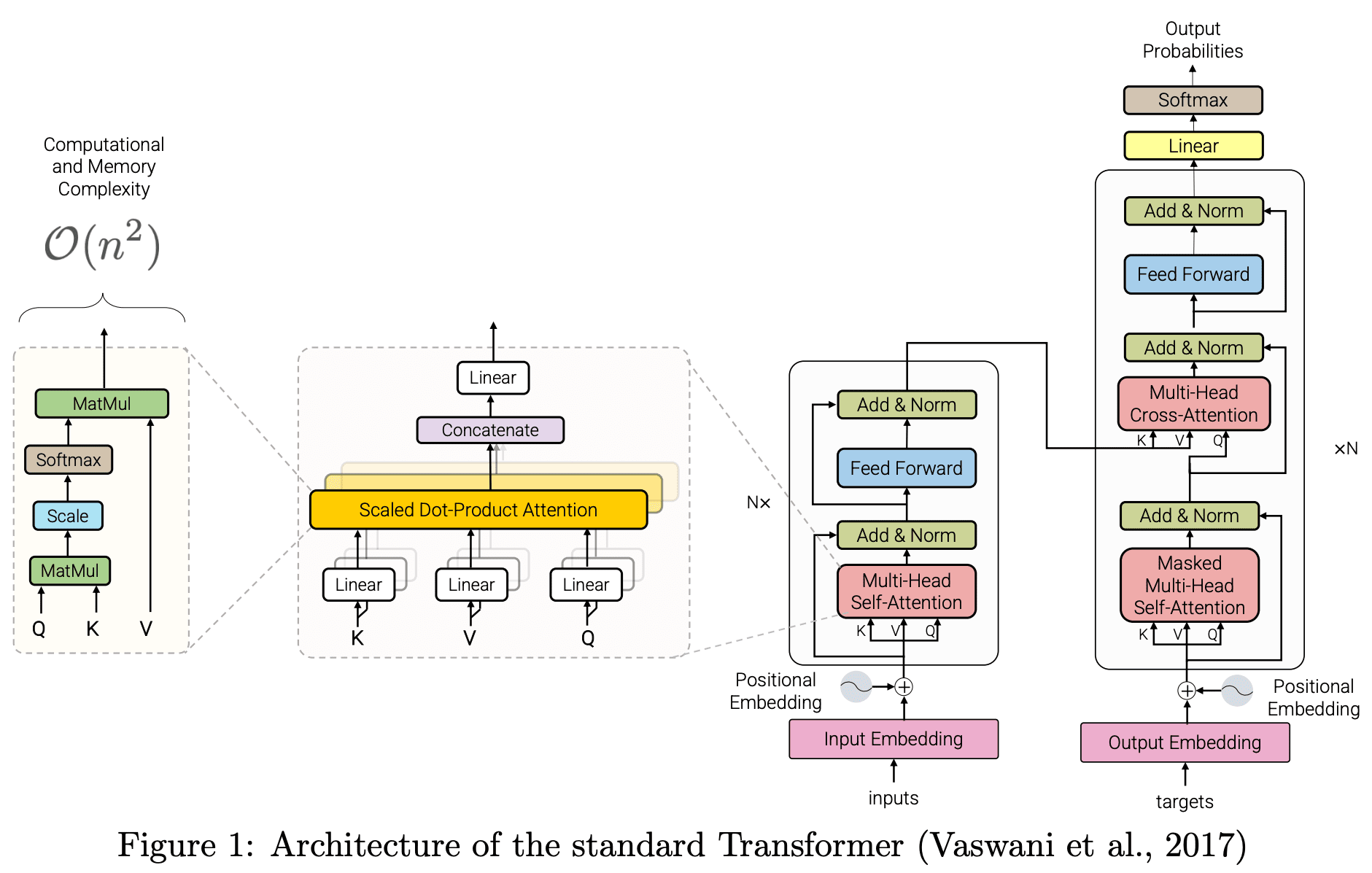
モデルを改良する方向性として,扱えるシークエンスの長さを増やす,学習に必要な計算量を減らす,メモリ使用量を減らす,並列計算しやすくする,パラメーターを増やす/減らす,扱えるデータ量を増やす/減らす,などをすぐに思いつきますが,これらを実現するための様々な工夫が発表されています.
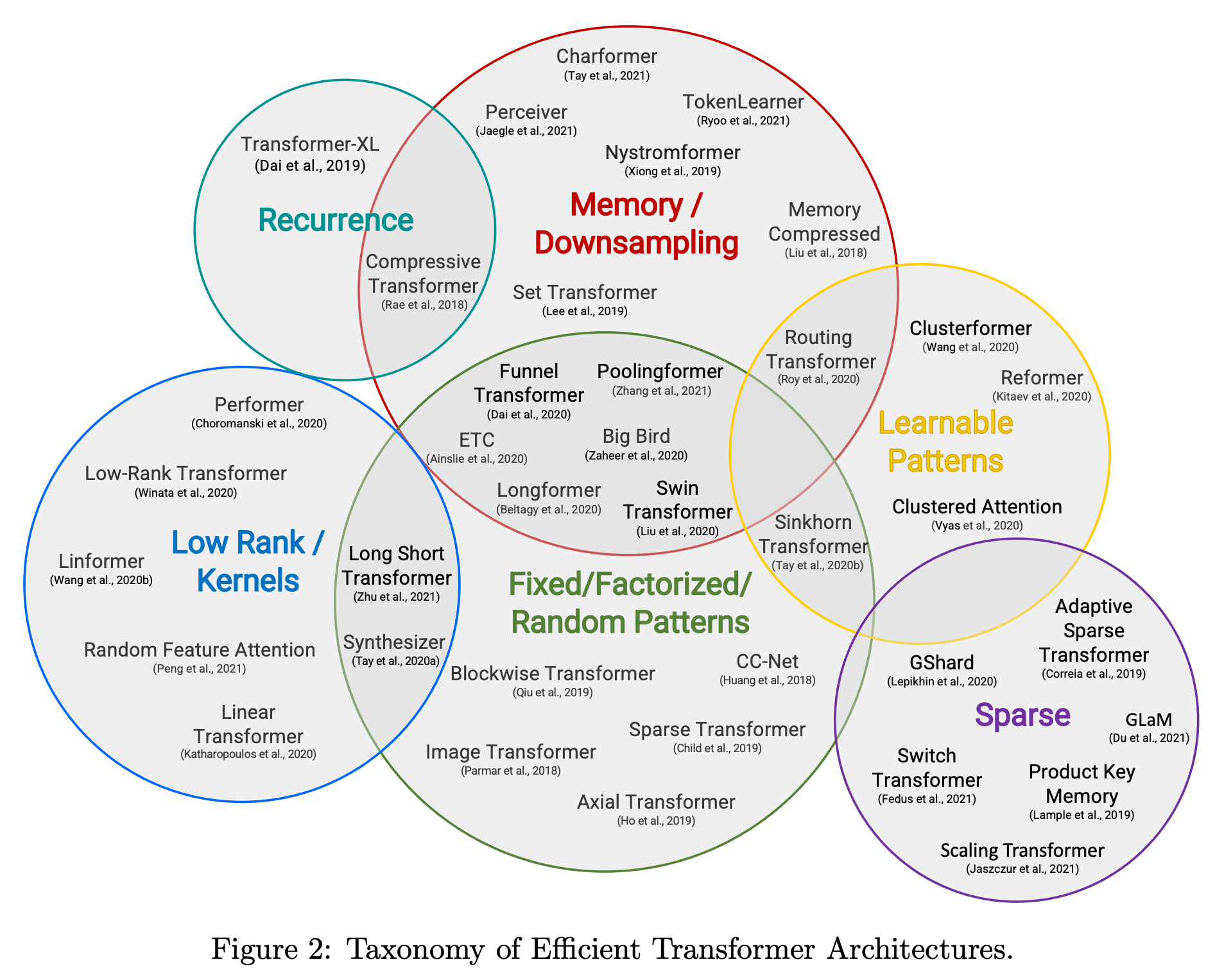
参考
- The Transformer model family
- notebooks/03_transformer-anatomy.ipynb at 884293a3ab50071aa2afd1329ecf4a24f0793333 · nlp-with-transformers/notebooks · GitHub
*1:[1706.03762] Attention Is All You Need Figure 1 より
*2:notebooks/images/chapter03_transformer-encoder-decoder.png at 884293a3ab50071aa2afd1329ecf4a24f0793333 · nlp-with-transformers/notebooks · GitHub より
{kind=link}
*3:notebooks/images/chapter03_transformers-compact.png at 884293a3ab50071aa2afd1329ecf4a24f0793333 · nlp-with-transformers/notebooks · GitHub より
{kind=link}
*4:https://arxiv.org/abs/2009.06732 Figure 1 より
*5:https://arxiv.org/abs/2009.06732 Figure 2 より